Hi folks. It's been quite a while since I last wrote a blog post, huh? Well, I've been busy with various projects at home and at work, so cut me some slack. To make it up to you, I've got a treat. The Soundcloud Liberator browser extension for Firefox
The source is available here
Usage & Rationale
This Firefox browser plugin allows you to download any track off of soundcloud, regardless of whether the download link is available. The usage is simple. You install the browser plugin, then visit any sound page on soundcloud (as in, the page for a single song). Once you're there, click the new FREE icon in your browser, and it'll open a tab that lets you download the track by saving it with your browser. It doesn't support downloading playlists right now. This browser plugin arose out of my frustration with soundcloud tracks that are uploaded under a Creative Commons license, but had no download link. If a track is Creative Commons, it's meant to be shared, right? I feel like by restricting download of tracks like that, it's against the spirit of the license. This was particularly annoying when I was specifically looking for CC content to use in other projects, and I'd find something great, only for there to be no download link. What's even more annoying is that unless you have some kind of pro account on soundcloud, downloads will be capped after a certain number, so even if a user intended for a song to be universally available, the download might be disabled just because the track had too many downloads already.
Development
At first, I had assumed that I'd be able to just look at the network traffic and grab my MP3 and be done with it. In fact, I vaguely remember being able to do this in the past. So I pulled up the network inspector in firefox, filtered it to media files and hit play. What I found was something else entirely.
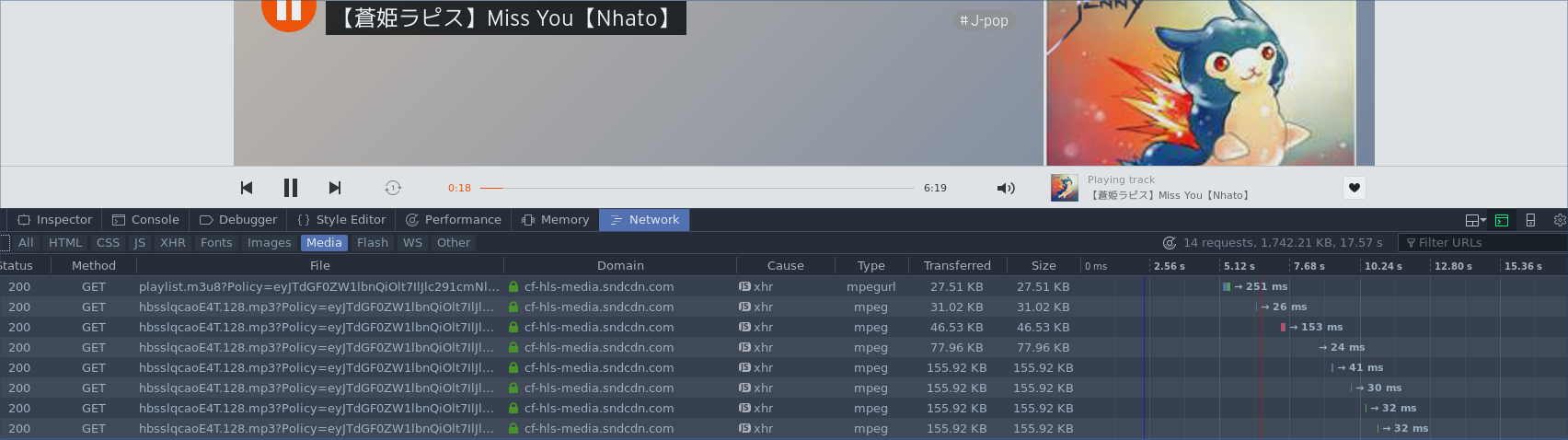
It seems that for some reason, soundcloud splits a file into segments. There's a couple different reasons this might be. For one, this might allow us to do parallelized download. Additionally, this might allow load balancing, or letting really really hot songs be spread across servers. If you picked any one of these URLs out, you could pull it up in a tab, but it'd only be a segment of the song. Let's take a look at one of the actual MP3 urls:
https://cf-hls-media.sndcdn.com/media/3352449/3512109/hbsslqcaoE4T.128.mp3?Policy=eyJTdGF0ZW1lbnQiOlt7IlJlc291cmNlIjoiKjovL2NmLWhscy1tZWRpYS5zbmRjZG4uY29tL21lZGlhLyovKi9oYnNzbHFjYW9FNFQuMTI4Lm1wMyIsIkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTQ5NjQ3NzYwN319fV19&Signature=h8BFZrBB1CHlEss~JTosvMS7alBB7awLVg-O64B~jljrCLdm1wERXceivavohPn42gzDdS9tCCmRovoPma5y6GZ0WqW5QaXUEQAfi-EYSMhtVuIyGgZTZ4h45GweXCpBxtGmzTILao1qj5Xe9n3OgWplYQFeVNFSTOXoxsa8gkRMf~LUddB9qPbQVxMBS8E1cZHQT5bADaYab8mXaRTkNfJAWB6dt7fqynZVKXkqK5Gsa7CoRon08JG2GtvkJt4EXLiOUESgGZtbFe6Ev6eLC0xz6vqu-Vw5DWyax~pMMe2QDqYGvrvWPx3AgH4-0zn2fpeuG2QCkLyrm6V5TjlXzQ__&Key-Pair-Id=APKAJAGZ7VMH2PFPW6UQ
Wow that is ugly. Tons of huge CGI nonsense makes this a fairly intimidating URL to look at. However, I quickly noticed a pattern.
https://cf-hls-media.sndcdn.com/media/3033128/3192788/hbsslqcaoE4T.128.mp3?Po...
https://cf-hls-media.sndcdn.com/media/3192789/3352448/hbsslqcaoE4T.128.mp3?P...
https://cf-hls-media.sndcdn.com/media/3352449/3512109/hbsslqcaoE4T.128.mp3?Polic...
After the media path, there's two numbers, and the number before is always less than the number after, and across URLs in the network log, they're monotonically increasing. Aha! So these aren't some random numbers. They are in fact some kind of units of time. Maybe seconds or samples. So what would happen if we found the URL with the highest ending sample, and replaced its start sample with 0? Like so...
https://cf-hls-media.sndcdn.com/media/0/3512109/hbsslqcaoE4T.128.mp3?Polic...
Well I tried it, and lo and behold, we got ourselves the full track, start to finish. What must be going on here is that the server will somehow split up the tracks on request, and serve it back. This doesn't rule out load balancing going on. There are probably replicas with all the data around. Or it could just be some mechanism to stop people from just grabbing the track outright. This totally sucks though. If I want to download a track, I gotta pull up my network view, seek to the end of the track to trigger the last song segment to download, and then patch the URL up. At this poit, I decided it would be a fun exercise to instead make myself a browser plugin to do it for me.
The first step was to identify how to make a browser plugin. I'm a firefox user, so I immediately went to the Firefox reference, and found this tutorial which covers how to hook HTTP requests and investigate their content. From there, I was able to build a listener for the browser.webRequest.onCompleted event, which I use in my final product.
The initial idea was to grab each of these ones, find the highest, and associate it with a normal track ID, so i could make sure the request belonged to the page I was visiting. I must admit, I never looked into whether there's separate instances of my listener running for each tab or not, and how the script behaved when the URL you're visiting changes, so instead i use an associative map of track IDs (actually it's mp3 filename, but I'll get into that later) to download links, and when you click on the button, it looks up the track ID in the map to see if the download link is available. The code itself to accomplish this is mostly string manipulation. It isn't particularly interesting. However, in order to index into that map, I need to get the track ID from the current URL. To do this, I need a soundcloud API token. However, the browser accomplishes these calls, and certainly it doesn't have an API token right?
Well in fact you can just take the token that the browser is using and substitute it in for a developer token. To facilitate this, i use my getClientId to pull it out of the CGI parameters. Very simple.
An issue quickly manifested itself, in that in order for me to get the highest sample number, the browser needs to make a request for it first. This was lousy, because it meant that in my initial version, the user needed to click on the end of the track in order to trigger the download. However, I found that the full list of audio segments is available in the form of an M3U playlist file that's downloaded by the browser when you visit a page. What's even better is that M3U is a text-based format. You'll see that in my final code, there is no longer any hooks to listen for the HTTP requests for individual songs. Instead, I simply listen for the M3U and parse out the last track, which, being in chronological order, will always have the highest sample in it.
However, there's one last issue. When we read our M3U file and get the MP3's, we have no way of getting the track ID from the MP3 url, since it has no info like that in it. So we must save the files into our map just by the filename. But there's no way exposed in the public API to go either from an MP3 filename to a track ID or vice-versa. I seemed to be SOL after quite a bit of work... However, after reading through the HTTP requests that are made, I found an interesting API call:
/tracks/{trackID}/streams
This appeared to do exactly what I wanted it to: resolve the URL to the actual mp3 name. However, to request that MP3 file, we still need some magical CGI tokens on the end, so I wasnt able to just use this for anything, however that could be a possibility if I was able to cache the policy token stuff at the end of the files. In fact, using the policy token stuff did work. Apparently it's valid long enough for me to reuse it later. I don't know how long it expires, and eventually it will likely leave my cache stale, for which the liberator currently has no resolution. You have to just refresh the page.
This magic sauce is used in my resolveStreamInfo function which is used in the process of going from a track ID to a URL, which allows me to index into my map.
The rest of the code is fairly straightforward. We just wait for the user to click the button, and if they're on a soundcloud song page we try a lookup in our map, and spawn a tab with the full-length mp3 in it.
That's the long and short of it. I've used the plugin several times now, and it's integrated into my full browser. Hope you enjoy.